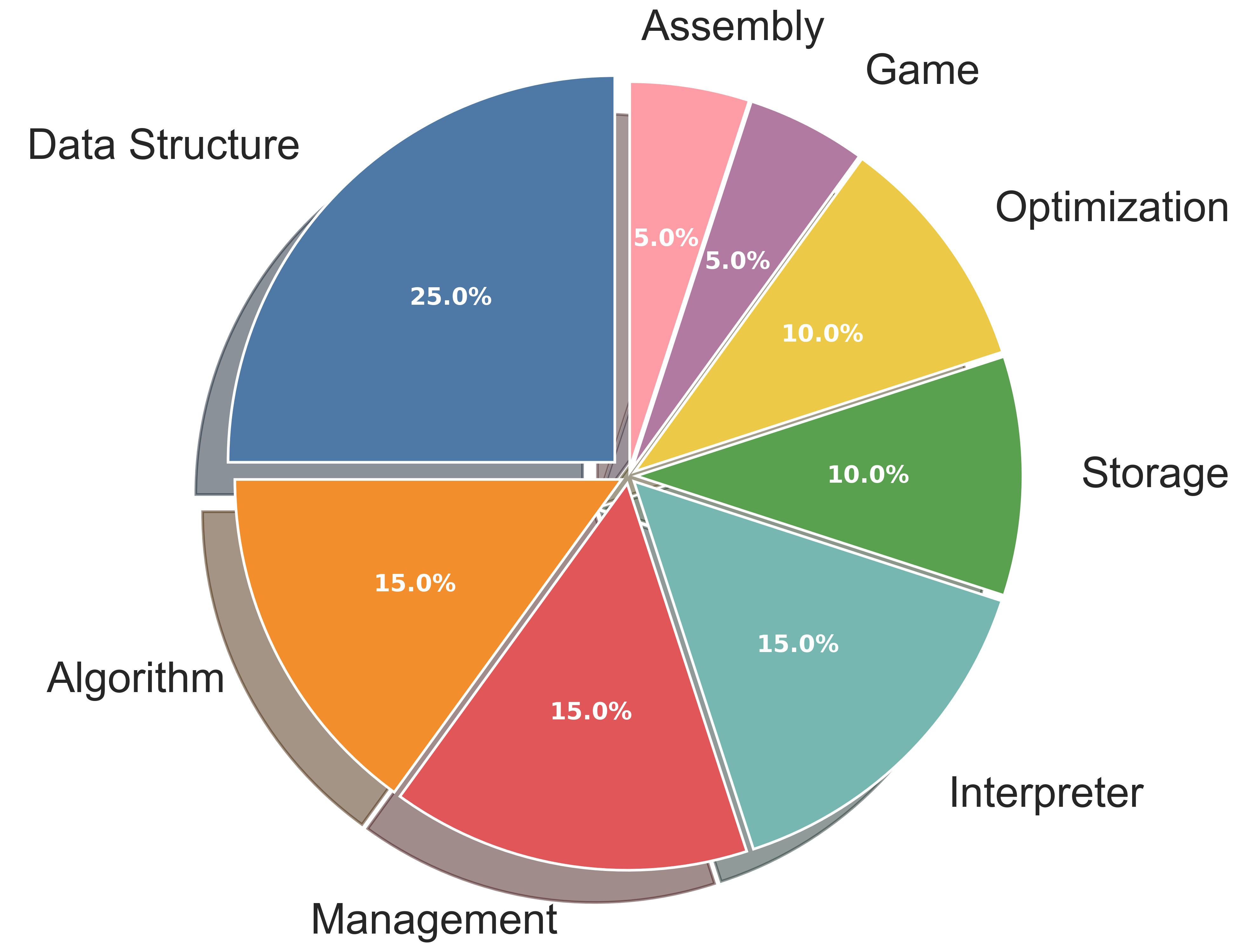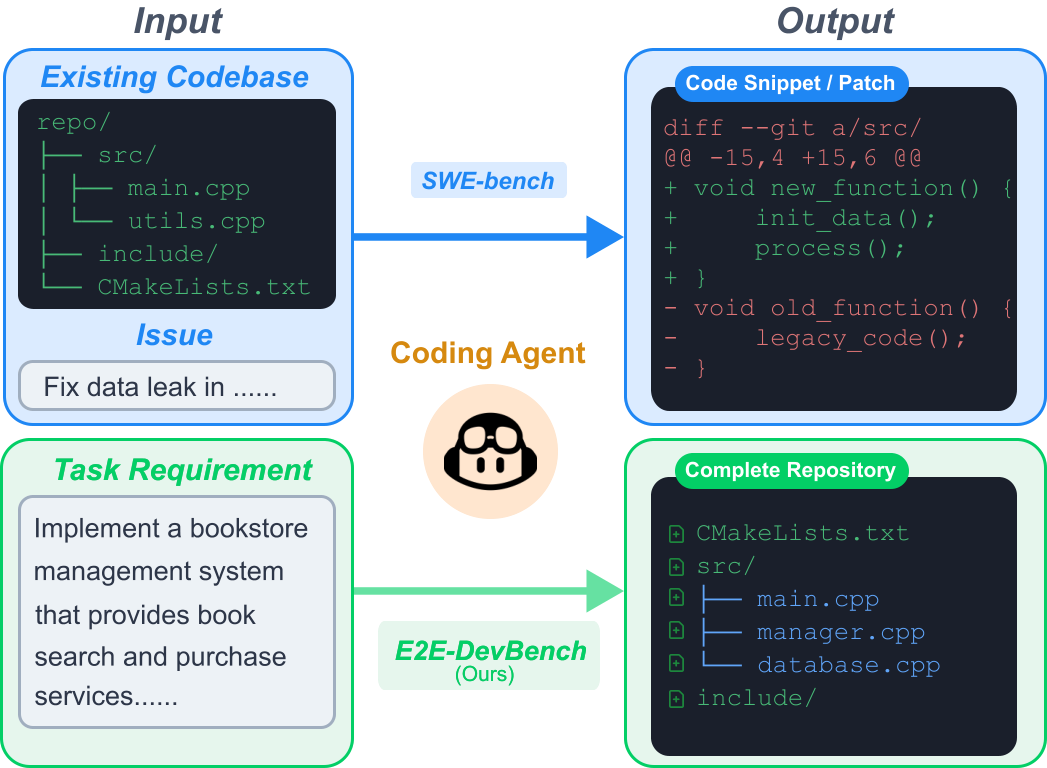
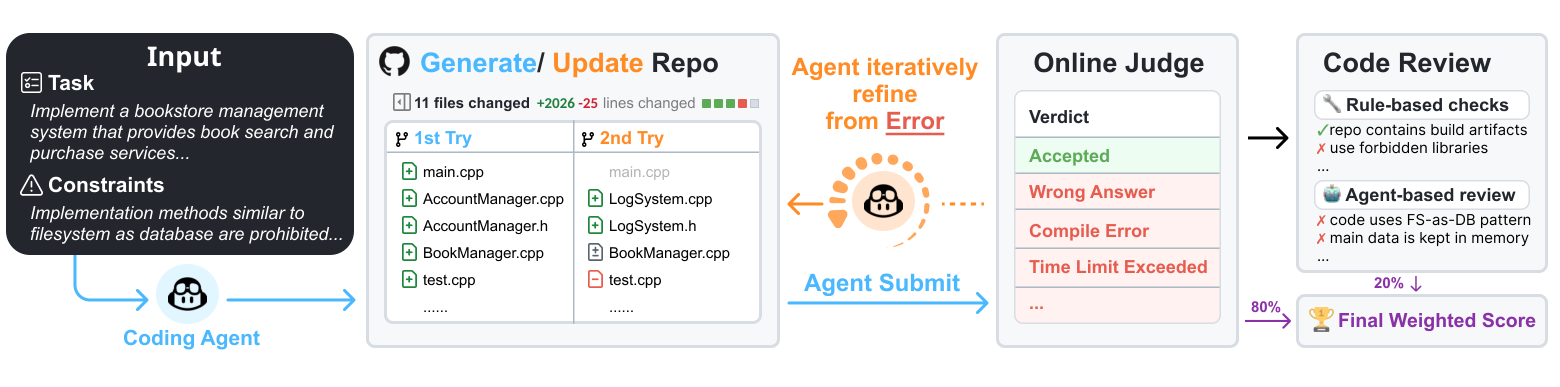
Performance on ProjDevBench across six coding agents and multiple LLM backends. Exec. represents the execution score from Online Judge, CR represents the code review score, and Final is the weighted combination (80% Exec. + 20% CR).
Codex
Cursor
Augment
Claude Code
GitHub Copilot
Gemini CLI